How do your computer store images?
To understand how graphic data is stored you first should be aware that there are two major kinds of graphics in the computer world : vector data and bitmap data.
Vector graphics define "what they represent" with lines, polygones or curves using key points. So the progams who have to display this sort of graphic draws the lines between the many key points and provides them with color or whatever.
An example to draw a line you should give your computer information about the coordinates of the two extremeties and some attribute like color and line thickness. This way you can represent any object which is easily drawn with lines (typicaly any geometric form). Moreover this way of desinging as evolved to todays 3-D wonderful imaging possibilities. Those new technologies add incredible FX to movies. (Have you already seen the new "Star Wars Trilogy?).
But this is an other story...
To come back to our purpose I would like to introduce you to bitmap data. Think of a picture as being only an array or "map" of colored dots and that is exactly what it is on your computer screen or printed page. If you don't believe me just use a magnifying glass to see the tiny dots. Do you agree? Ok. Now just learn that those very small dots are called pixels (for picture elements) and you know what a bitmap image is. Congratulations.
What's a bit? A bit is the smallest informations your computer can process. Thus each information is reduce to numerical values in terms of zeros and ones. Back to the pixel. A 1-bit pixel can only have two values 0 or 1. This way it can only be attributed two colors. Monochrome monitors and black-and-white printers use 1-bit data. Things that reproduce well in black and white usualy text and line drawings are stored as 1-bit per pixel data. A 4-bit pixel can be one of 16 colors (2*2*2*2=16). The number of bits per pixel naturally determinates the number of colors of the image (remember bitmap images are formed of pixels). This bit value is commonly called bit depth or pixel depth. Most widely used pixel depths are 1, 2, 4, 8, 15, 16, 24 and 32 bits.
Graphic Data representation
This is about how the computer interprets data to reproduce it. Usually bitmap files are broken down into two or more sections.
The simplest image image files have two or three parts : the header, bitmap data and sometimes the footer.
Header simply prepares the computer for the data that follows. It usually contains inforamtion to enable the computer to recognize the current file format and may include the following items.
Bitmap data is the essential part of the file. It comprizes the color values of each pixels in the image. Then, computer reads all these values and reproduces them on the appropriate device. Using the information in the header it can reproduce each pixel value of the image in the proper place.
The footer is an optionnal addition consising in omitted data. Most often this data has been omitted in the header due to version changes.
Compression Schemes
As users demand greater graphic quality in their computer applications, the amount of data required increases rapidly. Demand grows certainly quicker than storage capabilities and this as highlightenned the need for efficient compression techniques. Internet and the rise of multimΘdia applications have motivated are the most demanding in data compression. The question is how to store the same information in a lower amount of bits.
Hey ! Stop ! What is compression ?
Allright. Compression is just a method to store data more efficiently, that means "squeezing the air out of data".
Usual compression schemes take advantage of three common qualities of graphic data ; they are often redoundant, predictable or unnecessary.
RLE compression
Run Lenght Encoding is a lossless compression technique. That means that no data is lost in the process of "shrinking". this method usez redoundancy in the easiest possible way to reduce memory size.
This scheme replaces a serie of repeated values by a single value and a count. An example using letters to represent values :
AAABBBBBBCCCCCBDD
will be replaced by :
3A 6B 5C 1B 2D
This approach is often implemented in paint programs and works well whit images simple images containing large continuous color areas. But if a file as very small continuous regions (for example scanned photographies) it could cause the file to grow. That is simply explained by the fact that each continuous area is stored in two bytes. Typically using RLE compression on an image represented like that ...
ABCDEFGHI
1A1B1C1D1E1F1G1H1I
... will double the size of the file !
Many file formats use this compression scheme including : BMP, MacPaint, TIFF, PCX ...
Huffman compression
Huffman encoding is a common scheme for compression. It works by substituing more efficient codes for data. Since in was created in 1952 for stroring text files, it has spawned many variations. The basic scheme is to assign a binary code to each unique value, with code varying in lenght. Using shorter code for more frequently occuring values result in data compression (sometimes but not always !)
An example :
If there are 4 different values : XXYZZZZYYZWWWWWWW
The frequencies with which they appear are as follows :
7:W / 2:X / 3:Y / 5:Z
Using this information it's easy to build a binary tree. The basic algorithm pairs together the least frequently occuring elements; this continues until all pairs are combined.
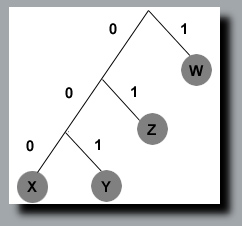
The least frequent values in this example are X and Y, so they make up the first pair; X is assigned the 0 branch and Y the 1 branch. The combined frequencies of X and Y equal 5 and are assigned the 0 branch of the tree and Z is assigned the 1 branch. The tree continues like that.
What are the results ?
X will be assigned 000, Y = 001, Z = 01 and W = 1.
Here is were the compression can be obtained : the most frequent values are assigned the shortest code ... and the necessary longer code is applied less frequently to the less frequent values. Yet no code is longer than it has to be !
To be efficient Huffman encoding requires a precise encoding algorithm and relies on the kind of image it is applied to. Maximal efficiency of this compression scheme is 8:1 and varies strongly with the different file formats.
Huffman encoding tends to perform less well for files containing large areas of identical pixel values, which can be better compressed using RLE or other encoding.
Furthemore, Huffman compression and decompression processes are relatively slow. When compressing ; the statistical model is firstly created and then at least data is encoded.
LZW is named after Welch, and building on work by Lempel and Ziv and is a more recent compression algorithm (Welch 1984). LZW is a proprietary method (UNISYS has been granted a patent) that has many popular variations.
This encoding scheme also builds a table but rather differently than the Huffman one. It is adaptative. That means it starts with a simple table and builds a more effective one as it goes along. The LZW exploits redundancies in the patterns it finds.
LZW encoding "tries" to identify patterns as long as possible and allocates them a unique code. For example :
XXYZWWXWXXYZ
In this example XXYZ is found two times :
XXYZWWXWXXYZ
and thus XXYZ is assigned a unique code. Typically LZW provides ratios between 1:1 and 3:1, although highly patterned images can sometimes be compressed as much as 10:1.
LZW relies on finding patterns and thus noisy images (thoses with random variations in data variations) are hard to compress ! LZW encoding is used in GIF and TIFF formats.
JPEG compression
JPEG compression (see JPEG file format) are hard to explain as they use many methods for compressing images. It's the most well known lossy compression scheme. The lossy compression means that some data is lost in the compression process. Done the right way JPEG-compressed images show little or no degradation.
This compression sparates the chroma inforamtion from the luminance (brightness) information and this way takes advantage of the tolerance of the human eye's tolerance for lower color resolution. Next the image is broken up into smaller tiles and then applied a mathematical technique known as DCT (Discret Cosine Transform). After this transformation, single pixels no more exist.
This image file format separates any image in 8 x 8 pixel boxes and evaluate an average color value. This value is stored in the upper left corner of the pixels group, other pixels, the remaining 63, are assigned values relatives to the average. Then, JPEG reduces as many pixels values as possible to zero dividing each block by is quantization matrix.
Doing that the JPEG compression removes redundant image data but also can lose in image quality. Because each pixel previously changed to zero will get the average color value, color distinctions are definitively lost. That's why you should be prudent with JPEG compression format and use it at the smallest (quite absolute lossless !) ratio until you are an expert with it.
![]()